2019 年 10 月 5 日 Vue3.0 pre-alpha 版本正式发布,之后数个月历经 500 多个 PR,1000 多个 commit,终于在 2020 年 1 月 4 日正式发布了 Vue3.0 alpha.1 版本。Vue3.0 的核心代码基本完成,截止目前为止剩下的主要工作就是服务端渲染,Vue 团队也正在积极进行中。
响应式 API 的代码也基本稳定,不会再发生太大的变化(packages 里的 reactivity 包),下面我将从源码分析 Vue3.0 的响应式原理。
Vue3.0 的响应式 API
1 | <template> |
Vue3.0 使用 setup 函数作为整个组件的入口点,使用直接导入的 onXXX 的函数注册生命周期的钩子,并在页面中使用 return 出来的变量。整个写法对比 Vue2.0 是会有一些变化,这里我们对于生命周期这些跟组件有关的代码不做讨论(属于 packages/runtime-core 包)。
而在响应式中最重要的就是剩下的 4 个 API。ref 和 reactive 都是将传入的参数转化为响应式对象的方法,区别在于 ref 是将基本数据类型(string,number,bool等)转换成响应式数据,而 reactive 是将其他数据类型转换成响应式数据。为了保证基本数据能够实现响应式,ref 会将基本数据包装一层,因此在上文代码中,想要取到 count 的值时,需要使用 count.value,而在模板中,自动会拆开(unwrap),因此可以直接使用 count。computed 与 vue2.0 作用一致,代表计算属性。watch 用来监听内部逻辑中的状态,每次依赖变动都会执行一次。
Vue 的特性之一就是数据驱动视图更新。所谓响应式就是当数据变化时,会自动更新需要变化的视图部分。与 Vue2.0 不同的是,Vue3.0 使用 monorepo 的结构,将响应式的代码单独抽成了一个包 – reactivity,也意味着你可以在非 Vue 的项目中,单独引用这个包使用响应式数据。
源码结构
这边还是先讲解下源码的文件结构,方便下文看起来更清晰。
1 | // packages/reactivity |
其实代码逻辑基本都在 baseHandlers.ts,collectionHandlers.ts,computed.ts,effect.ts,reactive.ts,ref.ts 这 6 个文件里。index 是对外暴露 API 的文件,lock 里包含可以修改全局是否响应式的变量和方法,operations 是方法劫持触发依赖变动类型对应的常量。当然这里面会用到一些工具函数,都来源于 packages/shared,后面讲解的时候,我会直接把这些工具函数一起放到代码中分析。
数据劫持
Vue2.0 使用了 Object.defineProperty 来进行数据劫持,其实它是在初始化的过程中将对象的每个属性进行代理,而 Vue3.0 使用了 Proxy 和 Reflect 的组合,将整个对象直接进行了代理。区别是在 Vue3.0 不再需要通过 vm.$set 和 vm.$delete 方法来实现响应式地新增和删除属性,不需要覆盖数组的原生方法,而且对于数组的监听不会破坏 JS 引擎的渲染,会有更好的性能。
Proxy 的数据拦截
1 | const data = { name: 'kpl' } |
Proxy 和 Reflect 的具体用法可以看一下阮老师的 ES6入门。为什么在 Proxy 里的 get 函数不直接返回拦截到的属性,而是要调用 Reflect 这个 API呢?
首先,Proxy 支持拦截共有 13 个方法,Reflect 同样拥有这一一对应的 13 种方法。这些方法包括了一些语言内部的方法(比如 Object.defineProperty),这些方法有时在使用过程中会抛出错误,而 Reflect 遇到这种情况会返回 false。
Proxy 对象可以方便地调用对应的 Reflect 方法,完成默认行为,作为修改行为的基础。也就是说,不管 Proxy 怎么修改默认行为,你总可以在 Reflect 上获取默认行为。
Vue3.0 响应式原理图
我梳理了一遍 Vue3.0 中对于数据代理,方法劫持,依赖收集和触发的流程,画了以下的原理图。刚开始看可能会有点绕,把后面的源码解析看完之后再来看这张图就会有更清晰的理解。
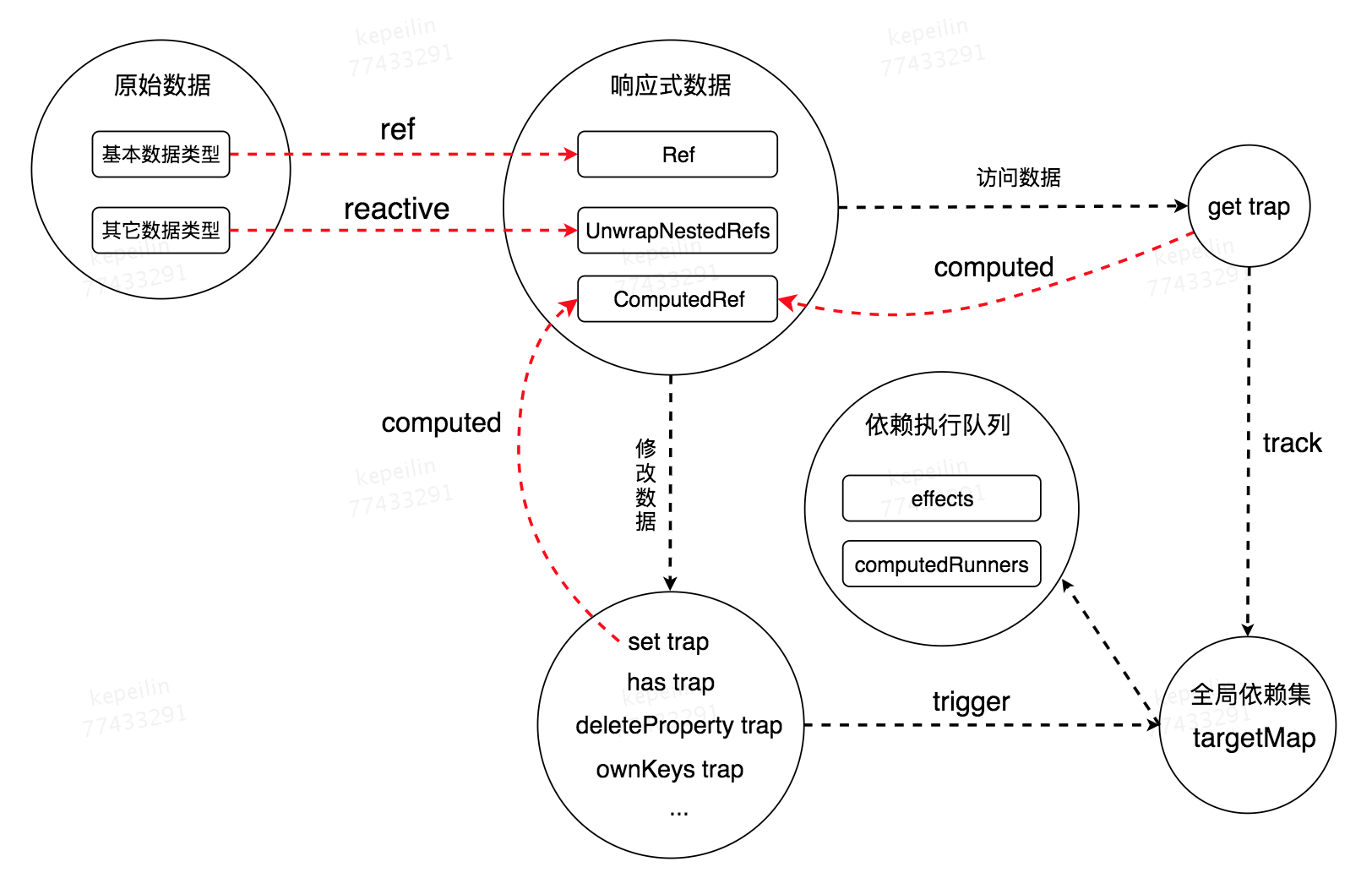
Reactive
尽管 Proxy 能够直接代理对象,但实际上也只能代理一层属性,对于对象内部的深度侦测,还是需要手动递归实现。当然,递归 Proxy 会存在性能隐患,当数据量较大的时候,递归 Proxy 会消耗比较大的性能。Vue3.0 里面是如何避免多余的性能损耗呢?
Vue3.0 里通过缓存原始数据和代理数据的映射关系集合,避免同一个数据被多次重复代理。同时在使用 reactive 生成响应式数据时,并不会递归,只有在访问响应式数据触发 get 的 trap 时,才会嵌套递归属性进行代理劫持(与 Vue2.0 在初始化时就会进行依赖收集不同,这个在讲解 handler 函数的时候会细说)。
1 | const rawToReactive = new WeakMap<any, any>() // 原始数据 -> 响应式数据 |
为什么使用 WeakMap 和 WeakSet 来保存映射数据集合呢?因为 WeakMap 和 WeakSet 保存的对象都是弱引用,只要所引用的对象的其他引用都被清除,垃圾回收机制就会释放该对象所占用的内存。因此使用这两个数据结构能够更好地减少内存开销,除此之外还拥有更高的搜索查询效率。
Vue3.0 里主要使用了三种响应式的方法,reactive, readonly 和 shallowReadonly。
1 | export function reactive<T extends object>(target: T): UnwrapNestedRefs<T> |
这边可以看到这三种方法其实都是调用了 createReactiveObject 这个方法,等会我们就看看这个方法。reactive 是返回响应式数据,readonly 是返回只读响应式数据的,那么 shallowReadonly 这个方法是干什么的?它会返回一个只有最外层是只读响应式数据的对象,同时它不会递归地将内部数据进行响应式地代理。它主要用在有状态的组件里创建的 props 代理对象。
接下来先讲下后面方法中会用到的几个工具函数。
1 | // 判断是否是对象 |
其实笔者在项目里也写过不少 TS 代码,但看了源码之后才发现自己的 TS 也只是半吊子水平,从中还是学到了很多。isObject 函数入参使用了 unknown 这个顶级类型,而不是 any,能够避免函数内对入参的任意操作(无法被除 unknown 和 any 以外的类型赋值)。同时函数返回类型使用了类型谓词,使用 Record<any, any> 而不是 object,因为 TS 允许访问 Record<any, any> 类型对象的任意属性而不会报错。canObserve 说明了哪些数据是可观察的。非 Vue 组件,非 DOM 节点,属于 isObservableType 定义的类型且不是不可响应数据。
1 | function createReactiveObject( |
虽然代码不多,但我们还是会存在几个疑问:
1.void 0 是什么意思?
其实就是 undefined。源码使用 void 0 代替 undefined,首先是因为 undefined 在局部作用域下会被重写,而 void 不会被重写, 且 void 0 拥有更少的字节数。事实上,不少 JavaScript 压缩工具在压缩过程中,正是将 undefined 用 void 0 代替掉了。
2.为什么要区分数据类型使用不同的 handler 函数?
Vue3.0 里使用了 baseHandlers 和 collectionHandlers 两个文件来处理 handler 函数。其中 collectionHandlers 文件是专门来处理集合类型数据(Map,Set,WeakMap,WeakSet),为什么集合类型数据需要单独的处理函数呢?
因为这些集合类型都使用了所谓的“内部插槽”,访问属性的时候是直接通过内置方法(this),而不是通过 [[Get]]/[[Set]],Proxy 无法拦截该内容。因为使用 Proxy 代理集合类型之后,this=Proxy,而不是原始对象,就会访问不到。因此我们需要做一层函数劫持,修改 this 的指向为原始映射即可。
baseHandlers
baseHandlers.ts 一共向外暴露出三个方法,mutableHandlers,readonlyHandlers 和 shallowReadonlyHandlers。对应上文提到的三种响应式方法 reactive,readonly 和 shallowReadonly。
1 | // LOCKED 是一个全局开关,锁住情况下数据不可变 |
其实这边可以看到其实暴露出来的三个 handler 方法其实都只劫持了 get,set,has,ownKeys 和 deleteProperty 这 5 个方法。get 和 set 好理解,has 其实劫持的是 propKey in proxy 的操作,ownKeys 可以劫持 Object.getOwnPropertyNames(proxy),Object.getOwnPropertySymbols(proxy),Object.keys(proxy),for...in 方法,deleteProperty 劫持 delete proxy[propKey] 方法。
Get
先来看 get 的劫持方法 createGetter:
1 | export const isArray = Array.isArray |
对于 get 拦截的处理函数还是比较清晰的。
刚开始看到 arrayIdentityInstrumentations 这个函数的时候没有明白它的作用是什么,只能去仓库查看相应的 commit。从该 单测 发现,因为 includes, indexOf, lastIndexOf 三种方法都是使用 strict equality 来判断查找元素的关系,如果响应式数据(数组)在 push 进一个引用类型的数据后,使用上述三个方法会发现匹配不到添加进的数据。因此不代理这三个方法,就能正确得到对应的匹配关系。
之后对于 ES6 的内置 Symbol 属性不收集依赖,对于 shallowReadonly 的数据只响应式代理到最外层,Ref 的数据因为是基本类型数据的包装,内部不会有嵌套数据,因此也不需要再递归处理,剩下的就需要手动递归代理。Vue3.0 是通过 track 函数来收集依赖,具体会在讲到 effect 文件时进行分析。
Set
再来看 set 的劫持方法 createSetter:
1 | export const hasChanged = (value: any, oldValue: any): boolean => |
createSetter 的源码加上官方的注释也蛮容易理解的,Vue3.0 通过 trigger 来实现依赖的触发(也是会在 effect 文件中再具体分析)。除此之外,当然会有几个疑惑的地方:
1.hasChanged 函数里为什么会有 (value === value || oldValue === oldValue) 这段逻辑?
因为 NaN !== NaN,所以加上这段逻辑是为了排除 NaN 的干扰。
2.为什么 isRef(oldValue) && !isRef(value) 这种情况不需要触发依赖?
因为 Ref 数据结构中本身有劫持 set 函数的逻辑(里面会触发依赖),所以不需要再多触发一次依赖。
3.target === toRaw(receiver)这段逻辑什么意思?
// don’t trigger if target is something up in the prototype chain of original
源码上有这段注释,意思是如果是原始数据原型链上的数据操作,不做任何触发监听函数的行为。还是不太明白,我就把这一行注释掉,跑了遍单测,从这个 测试用例 中终于看明白了。receiver 一般是被 Proxy 代理后的对象,但 handler 的 set 方法也有可能在原型链上或以其他方式被间接地调用(因此不一定是 proxy 本身)。
1 | Object.setPrototypeOf(child, parent) // child.__proto__ === parent true |
如上通过 Object.setPrototypeOf 方法能够改变目标对象的 proto,如果 child 和 parent 是 2 个 Proxy 代理对象,此时对于 child 来说,target 就不等于 toRaw(receiver)。对于 child 来说进行 set 操作不应该改变 parent 上的数据,因此对于原始数据原型链上的数据操作,不会触发监听函数。
deleteProperty, has, ownKeys
还有三个要劫持的函数。源码很简单,加了几行注释,不再分析了。
1 | function deleteProperty(target: object, key: string | symbol): boolean { |
collectionHandlers
前文已经讲过了,Map,Set,WeakMap,WeakSet 这四种数据类型 Proxy 无法正常的拦截到所有属性。比如代理 set, delete 等方法会直接报错,当然访问的 get 方法还是能够正常拦截。因此,我们可以实现一个新的对象,它拥有集合数据类型对应的全部 API,通过 get 劫持代理到这个新的对象即可。
1 | function createInstrumentationGetter(instrumentations: Record<string, Function>) { |
接下来就是看 mutableInstrumentations 和 readonlyInstrumentations 这两个新对象的内部实现了。
1 | const mutableInstrumentations: Record<string, Function> = { |
可以看到在新对象中就是代理了 get, size, has, add, set, delete, clear, forEach 以及迭代器(keys,values,entries,Symbol.iterator)相关的一些方法。
先看几个工具函数:
1 | export function toRaw<T>(observed: T): T { |
前两个方法在前文都讲过了,toReactive 将原始数据转化为可变响应式数据, toReadonly 将原始数据转化为只读响应式数据, getProto 读取对象的 __proto__ 属性(获得原型对象)。
1 | function get(target: MapTypes, key: unknown, wrap: typeof toReactive | typeof toReadonly) { |
尽管 collectionHandlers.ts 文件的内容比 baseHandlers.ts 的要长很多,但是如果先看懂了 baseHandlers.ts 的代码,再去看 collectionHandlers.ts 的代码,会容易很多。collectionHandlers.ts 创建了一个新的对象去劫持所有的集合类型数据,因此在劫持函数内部总会先去获取原始数据和原始数据的原型方法,再将该方法绑定到原始数据去调用。
Reactive 小结
reactive 通过 ES6 的 Proxy 和 Reflect API 实现数据代理,从而转化成响应式数据,优点自然是性能更好,使用更方便,缺点就是不支持 IE11 以下的浏览器。同时通过 lazy access 避免嵌套递归不断 new Proxy 造成的性能问题,而不像 Vue2.0 时在初始化时就收集好所有的依赖。
Ref
前面已经说过,reactive 无法转换基本数据类型,而 Ref 通过一层包装来解决基本数据类型无法转换成响应式数据的问题。
先看下 Ref 的数据类型:
1 | const isRefSymbol = Symbol() |
尽管 Ref 里有个私有属性能够判断目标对象是否是 Ref 结构,但是在任意对象上查 symbol 属性会比普通属性慢得多,因此 isRef 里其实是通过 _isRef 这个属性来判断是否为 Ref 数据,而这个属性会在生成 Ref 的时候添加。而 Ref 的 value 属性是“解包装”类型,它其实是通过递归的 infer 来实现的。
这边简单讲下 infer,因为解包装类型贯穿了 Reactive 和 Ref 文件,如果不对它有所了解,还是蛮影响源码的阅读。
1 | type ParamType<T> = T extends (param: infer P) => any ? P : T; |
在这个条件语句 T extends (param: infer P) => any ? P : T 中,infer P 表示待推断的函数参数。
整句表示为:如果 T 能赋值给 (param: infer P) => any,则结果是 (param: infer P) => any 类型中的参数 P,否则返回为 T。
接下来看个例子:
1 | interface User { |
在 TypeScript 2.8 之后的版本,引入 infer 特性之后,也内置很多与 infer 有关的映射类型,比如 ReturnType,ConstructorParameters,InstanceType 等等。接下来就来看看解包装类型是怎么样的。
1 | type UnwrapArray<T> = { [P in keyof T]: UnwrapRef<T[P]> } |
从代码中我们得知,Ref 的 value 结构可以是任意类型,但绝不能被 Ref 类型嵌套过,无论是 Ref<Ref<T>> 亦或是 Array<Ref>,{ [key]: Ref } 等等。
之后再看如何生成 Ref 数据:
1 | const convert = <T extends unknown>(val: T): T => isObject(val) ? reactive(val) : val |
在生成 Ref 的时候,会增加 _isRef 的属性,用来给 isRef 函数识别。Ref 内部同样对 get 和 set 函数做了拦截,也刚好对应了 Reactive.ts 中的 createGetter 函数里,对 Ref 类型的数据不收集依赖,直接返回它的 value 值。
还有 2 个 Ref 相关的方法:
1 | // 将目标对象里的每个 key 都转成 Ref 结构 |
Convert a reactive object to a plain object, where each property on the resulting object is a ref pointing to the corresponding property in the original object.
从官方文档可以看到,toRefs 是用来将响应式数据转化成普通对象,但是结果对象的属性都是 Ref 类型,依然具备响应式能力。
为什么 toProxyRef 函数里返回的 Ref 对象没有收集依赖和触发依赖?
前文也讲过,在 reactive 里对于 Ref 类型是不收集依赖也不触发依赖的,难道 toRefs 返回的值就不具备响应式的能力了吗?看下面的例子:
1 | const a = reactive({ x: 1, y: 2 }) |
其实 x 和 y 已经被代理到了 a 的 x 属性 和 y 属性上,因此访问 x 和 y 或者改变它们的值时,a 的 set value() 和 get value() 函数会被触发,从而进行依赖的收集和触发。因此,vue3 中特意在 toRefs 返回的 Ref 数据中去掉 trigger 和 track 函数,防止依赖的重复收集和重复触发。
Effect
不论是 computed 还是 watch 都是基于 effect 做了封装。在这个文件里主要讲了依赖的收集和触发。
先看一下类型声明。
1 | export interface ReactiveEffect<T = any> { // 监听函数 |
然后直接看 effect 的代码。
1 | export const EMPTY_OBJ: { readonly [key: string]: any } = __DEV__ ? Object.freeze({}) : {} |
这里已经看到了之前 effect 配置项中多个属性的作用了,接下来就要看如何创建监听函数。
1 | const effectStack: ReactiveEffect[] = [] // 存放所有监听函数 |
如果是处于激活状态的 effect,会放到全局的 effectStack 里,之后执行原始函数的过程中,如果改变了或者访问了响应式数据的值,就会通过 trigger 和 track 来进行依赖的触发和收集。
这边会有个疑问,每次执行 effect 函数时,都会先 push 进 effectStack,执行完后又会 pop,那么什么情况下 effectStack.includes(effect) === true 呢?
从这个 单测 中我们可以知道,当 effect 的执行函数存在循环依赖时就会发生,因此需要保证循环依赖时依赖收集和触发依然正常。
接下来看看 trigger 和 track 这两个函数是如何实现的。
Track
track 是依赖收集的函数。
1 | type Dep = Set<ReactiveEffect> // 依赖集合 |
targetMap 就是全局存储依赖的地方,三层嵌套的结构,分别是原始数据 -> 属性 -> 依赖集合。
为什么全局已经有 targetMap 这个存储依赖的结构,每个 effect 内部还要用 deps 来保存依赖呢?
在前面的 createReactiveEffect 函数中已经给出了答案。每次向执行函数时,当 effectStack 里不存在此依赖时,都会执行一遍 cleanup 函数,通过内部保存的 deps 从 targetMap 中清空对应依赖映射的关系。执行 stop 函数时也是如此。
那么这里又有一个问题,为什么每次执行函数之前需要清空一遍自身的依赖呢?
从该 单测 我们得知,当函数内存在条件分支时,每次执行可能会造成依赖的数据不同,因此每次在执行前都需要重新收集一次依赖。
Trigger
trigger 是依赖触发的函数。
1 | export const ITERATE_KEY = Symbol('iterate') |
trigger 就是在响应式数据发生变化的时候,通过维护 effects 和 computedRunners 两个依赖队列,之后再调用 scheduleRun 执行依赖的过程。
Effect 小结
effect 里讲了如何收集依赖,依赖的管理和依赖的触发。
监听函数每次执行时候都会放入 effectStack 队列,并将此监听函数缓存为 activeEffect,执行完成后将该监听函数从 effectStack 队列弹出,并将 activeEffect 值改成 effectStack 队列中的最后一个监听函数。监听函数在第一次执行时通过 track 函数将此函数放到访问的响应式数据的依赖中,并统一保存在 targetMap 集合。而当响应式数据修改时,通过 trigger 函数触发,从 targetMap 中取出对应的依赖,根据监听函数的类别分别放到 computedRunners 和 effects 这两个依赖执行队列中。之后,按照顺序依此执行 computedRunners 和 effects 两个队列里的监听函数。
Computed
先来看几个工具函数和类型声明
1 | export const isFunction = (val: unknown): val is Function => typeof val === 'function' // 判断是否为函数 |
从类型声明可以看到 ComputedRef 就是拥有 effect 的只读的 Ref。
1 | export function computed<T>(getterOrOptions: ComputedGetter<T> | WritableComputedOptions<T>) { |
从源码中可以看到,进入 computedRef 的 value 是只读类型,但是只要在使用 computed 传入自定义的 set 和 get 函数后,我们同样能手动改变计算属性的值。(这点与 vue2.0 一致,同样是提供 set 方法后可以自定义改变计算属性)
源码中通过使用 dirty 这个标志位,有效避免了计算属性重复触发依赖的问题。因为当同时访问某个计算属性以及依赖这个计算属性的计算属性时,computed 的 getter 函数会被同时触发,若是不存在 dirty 标志位,会导致多次执行 trigger。大家可以看这个 单测。
总结
这边没有讲解 watch 这个 API 的原因是,其实它属于运行时的代码(packages/runtime-core/src/apiWatch.ts),但是实际上它的底层就是 effect,因此我们也能大概了解 watch 的作用和运行机制。当然,想要彻底了解 watch API 的同学还是建议去看下运行时代码,比起 effect 还是有所扩展的。
通读完文章的同学这时候可以再去看上面的原理图,相信会有更深的理解。
其实整个阅读源码的过程并不容易,也费了很大的功夫。包括很多 TS 的高级用法,琢磨作者的意图等等。同时,我也阅读了网上一些优秀的源码解析文章,有时候自己看不懂某块逻辑的时候看看别人的分析和想法马上就茅塞顿开了。当然也会有不少错误的解读,你必须自己结合代码上下文去判断。
看源码也有不少技巧,首先就是根据作者的注释去理解,然后再去合理利用单测,比如将某一块逻辑注释掉,跑一遍单测,看看哪个样例挂了,就能去“猜出”注释掉的逻辑的作用。还有 commit message,一样能读到作者的意图。Vue 的项目一向都是具备良好的 commit 规范,能让代码拥有很高的可读性,这点很棒。之前我也在团队大力推广 Angular 的 commit 规范– commitizen。如果是通过 PR 合进来的 commit,还可以去仓库翻阅那条 PR,PR 的作者会在里面清晰的写明该条 PR 的作用。
Vue3.0 使用 TypeScript 重写,在数据侦测上用 Proxy 代替 Object.defineProperty,提高了响应式的性能,也能让用户更自由地操作数据。同时 Virtual DOM 重构,采用“动静结合”的思想,大大提高 vdom 的更新性能。
从我开始阅读源码到写完这篇文章其实已经过去了几个月,Vue3 也已经进入了后续的优化和收尾工作。我很高兴终于完成了这篇文章,当然里面有不少内容属于笔者的推测,如果你对本模块的代码解析中任何一处说法有疑问或有纠错,非常欢迎你联系我,我会尽快改正!